Why Did So Many Ignore Warnings Before the Crash of 2021?
Tesla. Bitcoin. GameStop. The equity market as a whole. Even the bond markets. The list goes on. Why did so many investors ignore the warning signs that were flashing red before the Crash of 2021? And more importantly, what was different about those who did not ignore those warnings?
As always, there were many root causes that amplified each other’s effects.
Let’s start at the individual level.
Tali Sharot’s research has shown how humans have a natural bias towards optimism. We are much more prone to updating our beliefs when a new piece of information is positive (i.e., better than expected in light of our goals) rather than negative (“How Unrealistic Optimism is Maintained in the Face of Reality”).
Individuals seek more information about possible future gains than about possible losses (e.g., “Valuation Of Knowledge And Ignorance In Mesolimbic Reward Circuitry”, by Charpentier et al).
We tend to seek, pay more attention to, and place more weight on information that supports our current beliefs than information that is inconsistent with or contradicts them (known as the confirmation or my-side bias). Moreover, as Daniel Kahneman showed in his book, “Thinking Fast and Slow” this process often happens automatically (“System 1”). When we notice information that is not consistent with our mental model/current set of beliefs about the world, our subconscious first tries to adjust those beliefs to accommodate the new information.
Only when the required adjustment is above a certain threshold, the feeling of surprise is triggered, calling on us to consciously reason about its meaning, using “System 2”.
Yet even then, this reasoning is often overpowered by group-level factors.
Having spent so much of our evolutionary existence in a world without writing or math, humans naturally create and share stories rather than formal models to make sense of our uncertain world. Stories are powerful because they have both rational and emotional content; while that makes them easy to remember, it also makes them very resistant to change.
Another group level phenomenon that is deeply rooted in our evolutionary past is competition for status within our group. Researchers have found that when the result of a decision will be private (not observed by others), we tend to be risk averse. But when the result will be observed, we tend to be risk seeking (e.g., “Interdependent Utilities: How Social Ranking Affects Choice Behavior”, by Bault et al).
Other research has found that when we are engaged in social status competition, we actually have less working memory available for reasoning about the task at hand (e.g., “Increases in Brain Activity During Social Competition Predict Decreases in Working Memory Performance and Later Recall” by DiMenichi and Tricomi).
Another evolutionary instinct comes into play when uncertainty is high. Under these conditions, we are much more likely to rely on social learning and copying the behavior of other group members, and to put less emphasis on private information that is inconsistent with or contradicts the group’s dominant view. The evolutionary basis for this heightened conformity is clear – you don’t want to be cast out of your group when uncertainty is high.
It is also the case that groups will often share more than one story or belief at the same time. Research has found that “as a result of interdependent diffusion, worldviews will emerge that are unconstrained by external truth, and polarization will develop in homogenous populations” (e.g., “Interdependent Diffusion: The Social Contagion Of Interacting Beliefs” by James P. Houghton).
All of these group causes have been supercharged in our age of hyperconnectivity and multiple media platforms.
Finally, individual and group causes are often reinforced by organizational level phenomena.
As successful organizations grow larger, there is a tendency to recruit and promote people who have similar views. Growth also tends to increase the emphasis an organization places on predictable results, which causes them to penalize errors of commission (e.g., false alarms) more heavily than errors of omission (e.g., missed alarms).
Thus employees in larger organizations are likely to wait longer and require strong evidence before warning that danger lies ahead.
In his January 2021 letter to investors (“Waiting for the Last Dance”), GMO’s Jeremy Grantham explained why larger organizations are less likely to warn clients when markets are severely overvalued:
“The combination of timing uncertainty and rapidly accelerating regret on the part of clients [for missing out on gains as the bubble inflates] means that the career and business risk of fighting bubbles is too great for large commercial enterprises…
“Their best policy is clear and simple: always be extremely bullish. It is good for business and intellectually undemanding. It is appealing to most investors who much prefer optimism to realistic appraisal, as witnessed so vividly with COVID. And when it all ends, you will as a persistent bull have overwhelming company. This is why you have always had bullish advice in bubbles and always will."
In sum, that so many suffered large losses when the post-COVID bubble burst should come as no surprise. It was merely the latest version of a plot line that has been repeated for centuries in speculative markets.
The real lessons to be learned come from those investors who reduced their exposure and changed their asset allocations before markets suddenly and violently reversed (analysts are still searching – likely in vain -- for the cause of the market crash. Such is the nature of complex adaptive systems).
What did these investors do differently?
We know one thing they didn’t do – believe that they could personally overcome the very human and deeply rooted evolutionary biases noted above. Research says that odds against success in that endeavor are long indeed.
Rather than trying to conquer their personal biases, these investors established – and followed – investment processes that were designed to offset those biases and their emotionally charged effects.
For example, they didn’t fall prey to the “this time is different” myth, and used traditional valuation metrics to inform their asset allocation decisions. Their default conclusion was that the valuation metrics were right, and demanded very solid, logical and evidence based arguments to reject the signals they sent.
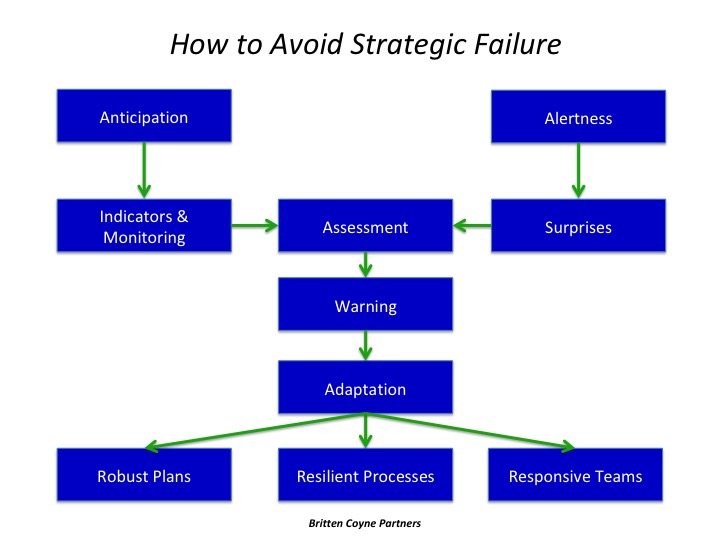
In their own forecasting, they followed best practices. They spent a lot of time making sure they were asking the right questions; they paid attention to base rates; they were disciplined about seeking out high value information to update their views; and they were always alert to surprises that warned their beliefs and models were incomplete.
They also sought out forecasts from a wide range of other sources that were based on different information and/or methodologies, and then combined them to increase their predictive accuracy.
And they focused their forecasting efforts on time horizons beyond the range of the algorithms, where human effort can still produce a profitable edge.
Most important, perhaps, is this timeless truth: The investors who avoided the Crash of 2021 weren’t any smarter than those who were wiped out. They were just more conscious of their own weaknesses, and as a result their investment processes followed a more disciplined approach.
As always, there were many root causes that amplified each other’s effects.
Let’s start at the individual level.
Tali Sharot’s research has shown how humans have a natural bias towards optimism. We are much more prone to updating our beliefs when a new piece of information is positive (i.e., better than expected in light of our goals) rather than negative (“How Unrealistic Optimism is Maintained in the Face of Reality”).
Individuals seek more information about possible future gains than about possible losses (e.g., “Valuation Of Knowledge And Ignorance In Mesolimbic Reward Circuitry”, by Charpentier et al).
We tend to seek, pay more attention to, and place more weight on information that supports our current beliefs than information that is inconsistent with or contradicts them (known as the confirmation or my-side bias). Moreover, as Daniel Kahneman showed in his book, “Thinking Fast and Slow” this process often happens automatically (“System 1”). When we notice information that is not consistent with our mental model/current set of beliefs about the world, our subconscious first tries to adjust those beliefs to accommodate the new information.
Only when the required adjustment is above a certain threshold, the feeling of surprise is triggered, calling on us to consciously reason about its meaning, using “System 2”.
Yet even then, this reasoning is often overpowered by group-level factors.
Having spent so much of our evolutionary existence in a world without writing or math, humans naturally create and share stories rather than formal models to make sense of our uncertain world. Stories are powerful because they have both rational and emotional content; while that makes them easy to remember, it also makes them very resistant to change.
Another group level phenomenon that is deeply rooted in our evolutionary past is competition for status within our group. Researchers have found that when the result of a decision will be private (not observed by others), we tend to be risk averse. But when the result will be observed, we tend to be risk seeking (e.g., “Interdependent Utilities: How Social Ranking Affects Choice Behavior”, by Bault et al).
Other research has found that when we are engaged in social status competition, we actually have less working memory available for reasoning about the task at hand (e.g., “Increases in Brain Activity During Social Competition Predict Decreases in Working Memory Performance and Later Recall” by DiMenichi and Tricomi).
Another evolutionary instinct comes into play when uncertainty is high. Under these conditions, we are much more likely to rely on social learning and copying the behavior of other group members, and to put less emphasis on private information that is inconsistent with or contradicts the group’s dominant view. The evolutionary basis for this heightened conformity is clear – you don’t want to be cast out of your group when uncertainty is high.
It is also the case that groups will often share more than one story or belief at the same time. Research has found that “as a result of interdependent diffusion, worldviews will emerge that are unconstrained by external truth, and polarization will develop in homogenous populations” (e.g., “Interdependent Diffusion: The Social Contagion Of Interacting Beliefs” by James P. Houghton).
All of these group causes have been supercharged in our age of hyperconnectivity and multiple media platforms.
Finally, individual and group causes are often reinforced by organizational level phenomena.
As successful organizations grow larger, there is a tendency to recruit and promote people who have similar views. Growth also tends to increase the emphasis an organization places on predictable results, which causes them to penalize errors of commission (e.g., false alarms) more heavily than errors of omission (e.g., missed alarms).
Thus employees in larger organizations are likely to wait longer and require strong evidence before warning that danger lies ahead.
In his January 2021 letter to investors (“Waiting for the Last Dance”), GMO’s Jeremy Grantham explained why larger organizations are less likely to warn clients when markets are severely overvalued:
“The combination of timing uncertainty and rapidly accelerating regret on the part of clients [for missing out on gains as the bubble inflates] means that the career and business risk of fighting bubbles is too great for large commercial enterprises…
“Their best policy is clear and simple: always be extremely bullish. It is good for business and intellectually undemanding. It is appealing to most investors who much prefer optimism to realistic appraisal, as witnessed so vividly with COVID. And when it all ends, you will as a persistent bull have overwhelming company. This is why you have always had bullish advice in bubbles and always will."
In sum, that so many suffered large losses when the post-COVID bubble burst should come as no surprise. It was merely the latest version of a plot line that has been repeated for centuries in speculative markets.
The real lessons to be learned come from those investors who reduced their exposure and changed their asset allocations before markets suddenly and violently reversed (analysts are still searching – likely in vain -- for the cause of the market crash. Such is the nature of complex adaptive systems).
What did these investors do differently?
We know one thing they didn’t do – believe that they could personally overcome the very human and deeply rooted evolutionary biases noted above. Research says that odds against success in that endeavor are long indeed.
Rather than trying to conquer their personal biases, these investors established – and followed – investment processes that were designed to offset those biases and their emotionally charged effects.
For example, they didn’t fall prey to the “this time is different” myth, and used traditional valuation metrics to inform their asset allocation decisions. Their default conclusion was that the valuation metrics were right, and demanded very solid, logical and evidence based arguments to reject the signals they sent.
In their own forecasting, they followed best practices. They spent a lot of time making sure they were asking the right questions; they paid attention to base rates; they were disciplined about seeking out high value information to update their views; and they were always alert to surprises that warned their beliefs and models were incomplete.
They also sought out forecasts from a wide range of other sources that were based on different information and/or methodologies, and then combined them to increase their predictive accuracy.
And they focused their forecasting efforts on time horizons beyond the range of the algorithms, where human effort can still produce a profitable edge.
Most important, perhaps, is this timeless truth: The investors who avoided the Crash of 2021 weren’t any smarter than those who were wiped out. They were just more conscious of their own weaknesses, and as a result their investment processes followed a more disciplined approach.